




13 января 26
На что способен ИИ сегодня, где он действительно полезен бизнесу, а где его возможности сильно переоценены?

 дата публикации
дата публикации
16.03.26
 минут
минут
10'
 формат
формат
![]() статья
статья
 автор
автор
Системы на базе Retrieval Augmented Generation (генерация с дополненной выборкой, RAG) — мощный инструмент для работы с корпоративными данными. В отличие от публичных моделей, типа ChatGPT и Grok, решения RAG точнее, безопаснее и позволяют «подключить» ИИ к актуальной внутренней информации без дорогостоящего обучения моделей. Однако их внедрение не всегда оправдано и не всегда приносит желаемые результаты. В этой статье мы разберем, где RAG-системы показывают свою эффективность, какие есть ограничения применения и что стоит учесть перед тем, как их использовать.
Retrieval Augmented Generation (генерация с дополненной выборкой, RAG) – метод работы с ИИ, при котором его ответы основываются на внутренних сведениях компании, переданных вместе с запросом человека. Эта технология использует нейросети для генерации ответов, объединяя два процесса: извлечение релевантных фактов из доступных источников и формирование ответа на основе этих записей с помощью большой языковой модели (LLM).
Простыми словами: вместо того, чтобы полагаться исключительно на знания, внедренные в выбранную модель ИИ во время обучения, RAG позволяет ИИ сначала найти необходимую информацию из внутренних и внешних источников, а затем сформулировать ответ на ее основе. Интегрируя факты из баз данных компании, ИИ улучшает точность и актуальность предоставляемых ответов.
Например, в фармацевтике вместо поиска досье по препаратам в сети интернет, как это делает иная модель ИИ, RAG формирует ответ из актуальных внутренних документов по препарату, а также подтягивает подходящие знания на базе ответов из кэша, таким образом предоставляя максимально точные сведения.
Для ритейла и электронной коммерции ИИ-помощники на базе RAG персонализируют ответы клиенту на основе истории его взаимодействия с компанией и товарами, а при отсутствии таковой предоставляют четкие факты о продукте без классического ответа обычных моделей «характеристики товара можно посмотреть в его карточке».
Большие языковые модели, такие как ChatGPT, Claude, LLaMA и прочие, обучаются на огромных массивах данных, но имеют фундаментальные ограничения:
RAG же эти проблемы решает, давая модели доступ к актуальным, проверенным и подходящим результатам в момент генерации.
В чём преимущества RAG:
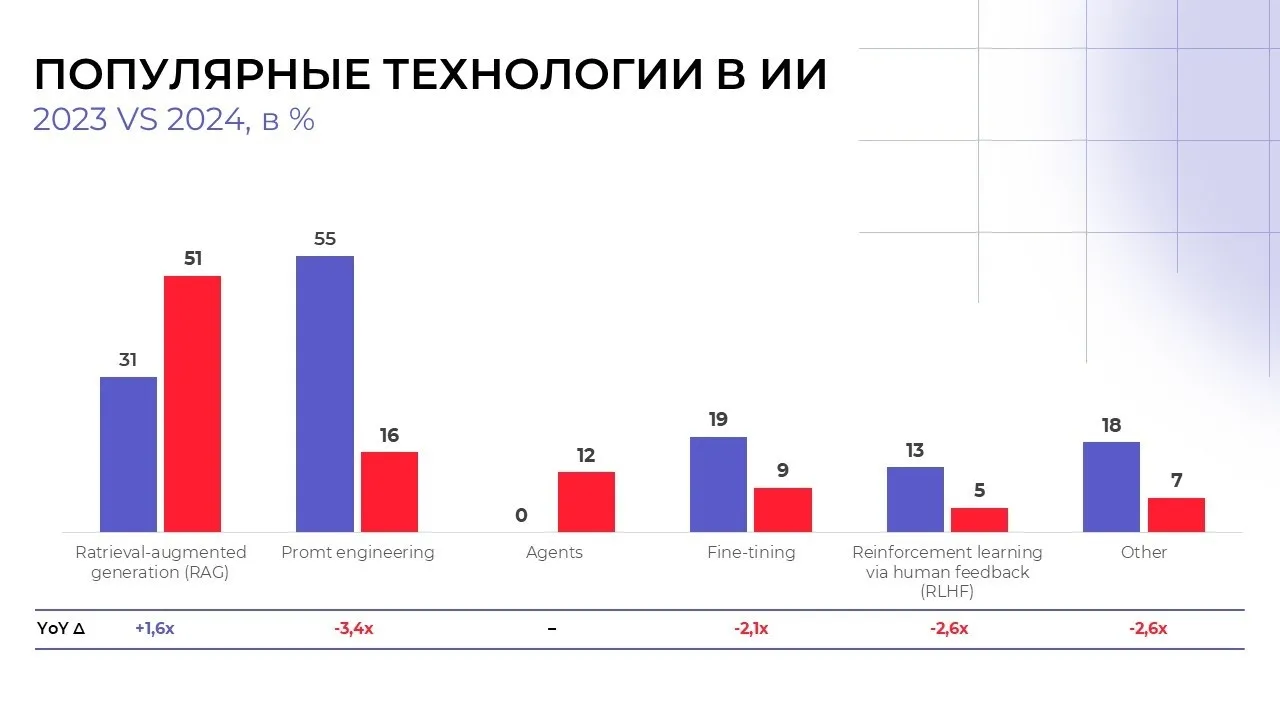
По результатам исследования Menlo Ventures, 2023 год показал значительный рост применения RAG-технологий в корпоративном секторе. По сравнению с предыдущими годами, использование RAG удвоилось, и в 2025 году ожидаются еще более высокие темпы роста. В корпоративных проектах более 70% решений на базе ИИ используют данную технологию, что делает её одним из ключевых инструментов для автоматизации и оптимизации процессов.
| Критерии | RAG | Fine Tuning | Knowledge Graph + LLM |
| Суть метода | Модель ищет релевантные документы в базе знаний и генерирует ответ на их основе | Дообучение модели на специфичных показателях компании | Структурированный граф знаний + генерация ответа моделью |
| Актуальность материалов | Всегда актуальны — обновляется база, не модель | Устаревают — нужно переобучение | Всегда актуальны |
| Стоимость запуска | Средняя | Высокая | Высокая |
| Стоимость поддержки | Низкая | Высокая (переобучение) | Средняя-высокая |
| Точность ответов | Высокая | Высокая в узкой области | Очень высокая |
| Галлюцинации | Низкий риск (есть источник) | Средний риск | Низкий риск |
| Сложность внедрения | Средняя | Высокая | Высокая |
| Масштабируемость базы знаний | Легко добавлять документы | Требуется переобучение | Требуется моделирование |
| Источники | Можно показать источник | Нет | Прозрачная логика связей |
| Лучше всего подходит для | Корпоративные помощники, поддержка, внутренние базы знаний | Специализированный стиль/тон, узкоотраслевая терминология | Сложные предметные области, медицина, юриспруденция, финансы |
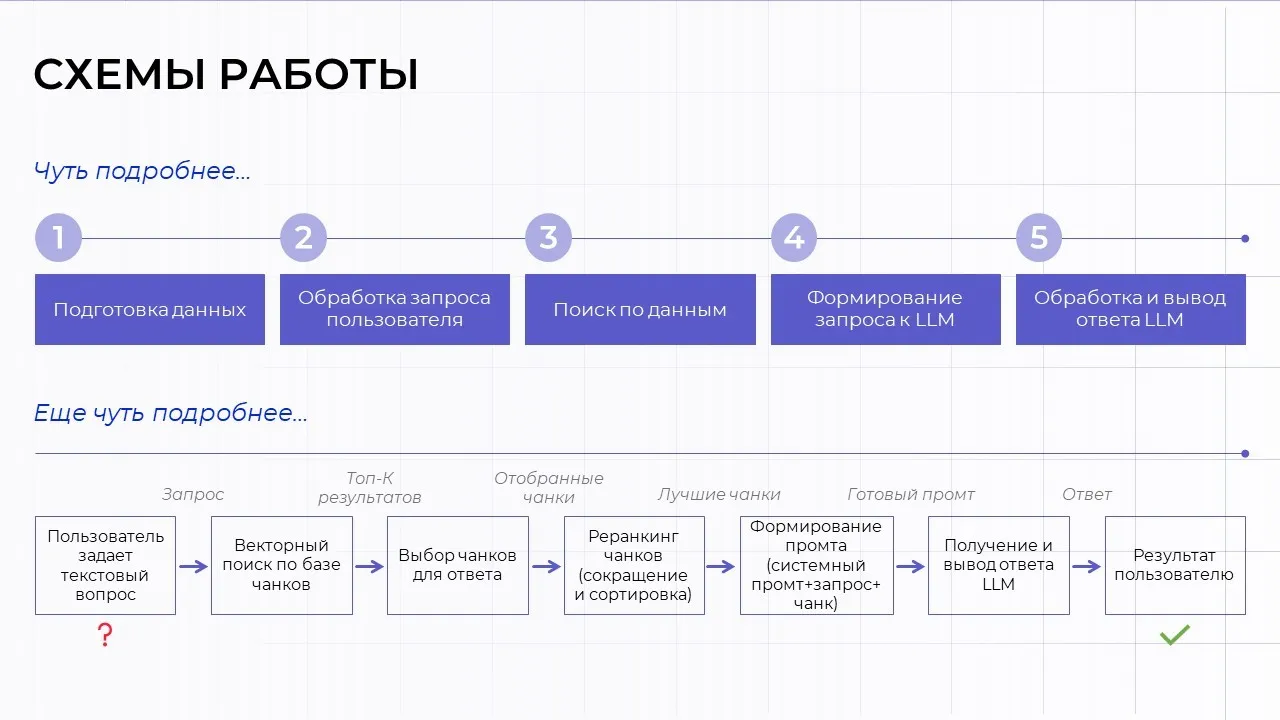
RAG – это модульная архитектура, в которой каждый компонент выполняет свою роль в цепочке «от вопроса пользователя до точного ответа». Архитектуру системы можно представить как конвейер, состоящий из двух основных контуров:
Оба контура включают множество компонентов, каждый из которых критически важен для качества итогового ответа.
Offline-контур – это фундамент системы. Этап подготовки материалов напрямую определяет качество ответов. Здесь происходит преобразование «сырых» документов в структурированную, доступную для поиска базу знаний. В этом контуре включаются источники сведений, загрузчики документов, разбиение информации на фрагменты, векторное представление текста (модели эмбеддингов) и формируется векторная база знаний.
Online-контур работает с пользователем. Запускается целая цепочка компонентов, работающих в реальном времени: обработка запроса, поиск релевантных фрагментов в базе знаний (ретривер), переоценка результатов поиска для улучшения их качества (ре-ранкер), формирование контекста и промта, генерация ответа. Продвинутые RAG-системы в этом контуре имеют дополнительные компоненты: кэширование, защитные механизмы, система оценки качества работы RAG, обратная связь и улучшение.
Архитектура RAG – это не просто «поиск + генерация». Это сложная, многокомпонентная система, где качество каждого звена влияет на конечный результат.
Можно выделить три ключевых этапа в процессе работы RAG-системы: индексация, извлечение и генерация.
На этапе индексации внешние записи разбиваются на фрагменты, так называемые чанки, для работы только с релевантными знаниями, после чего преобразуются в векторные представления* и сохраняются в векторной базе данных*. Здесь происходит подготовка сведений для работы с запросами.
*Векторные представления – преобразование текста в массив чисел, который отражает смысл текста. Информация ищется по «похожести» представлений текста в числовом пространстве.
*Векторная база данных – специализированный репозиторий, оптимизированный для хранения и быстрого поиска по векторным представлениям текста.
На этапе извлечения модель принимает запрос от пользователя, который так же преобразуется в векторное представление. Система выполняет семантический поиск по векторной базе и находит наиболее релевантные фрагменты документов. Они ранжируются по степени соответствия запросу. Здесь обрабатывается запрос пользователями происходит поиск по сведениям.
При генерации ответа, найденные фрагменты добавляются в контекст промта для языковой модели с целью обработки результатов. Далее, опираясь на предоставленные факты, а не только свои внутренние знания, модель генерирует и выдает пользователю максимально точный, актуальный и привязанный к конкретным источникам ответ. Здесь генерируется ответ и выдается пользователю.
Устранив эти препятствия, вы создадите незаменимого ИИ-сотрудника, который возьмет на себя рутину и даст команде ресурсы для выполнения стратегических задач.

Внедряя ИИ-систему для автоматизации бизнес-процессов, компании неизбежно сталкиваются с непростым стратегическим выбором: какой подход использовать и какую технологию положить в основу решения? Ведь неправильный выбор метода – это потерянные месяцы проектирования и разработки, сотни тысяч рублей, вложенные в инфраструктуру, которая не оправдала ожиданий и, в конечном счёте, разочарование от системы, которая красиво выглядит на демо, но не решает реальные бизнес-задачи.
RAG-системы заслуженно считаются одним из наиболее мощных и универсальных инструментов для корпоративной автоматизации. Они умеют работать с актуальными сведениями компании, снижают количество ошибок и галлюцинаций языковых моделей, обеспечивают прозрачность ответов через ссылки на источники. Однако и эта технология требует вдумчивого подхода к внедрению, грамотной настройки каждого компонента и чёткого понимания того, какие задачи она решает эффективно, а где её возможности объективно ограничены.
Не существует универсального решения для всех типов задач, и в некоторых случаях альтернативы, такие как простые чат-боты или сценарные системы, могут быть более эффективными.
Именно поэтому выбор подхода должен начинаться не с технологии, а с глубокого понимания бизнес-контекста: какие материалы есть в компании, как часто они меняются, насколько критична точность ответов, какой бюджет и какая команда готовы поддерживать систему в долгосрочной перспективе.


10:00

15:00


10:00





